


a lens on the magic of deliberation
Reasonable People #24: transcripts of discussions which allow people to overcome an intuitive bias

We’ve some new work out in preprint:
Karadzhov, G., Stafford, T., & Vlachos, A. (2021). DeliData: A dataset for deliberation in multi-party problem solving. arXiv preprint arXiv:2108.05271.
Project website: delibot.xyz
This project is led by Georgi Karadzhov, who is in the Natural Language and Information Processing group at the University of Cambridge, Department of Computer Science, as part of his PhD. Andreas Vlachos, also in Computer Science at Cambridge, is the lead supervisor. For this newsletter I’ll explain why I’m so excited about this work, and where I hope it will go in the future.
*
The background is a classic reasoning problem, the error it induces 90% of people to make, and the alchemy of group discussion.
Wason’s Selection Task
Peter Wason was a British psychologist of reasoning, and invented a card selection task which demonstrates the gap between people’s intuitive reasoning and formal logic (Wason, 1968). Here are the instructions, as we showed them to our participants:
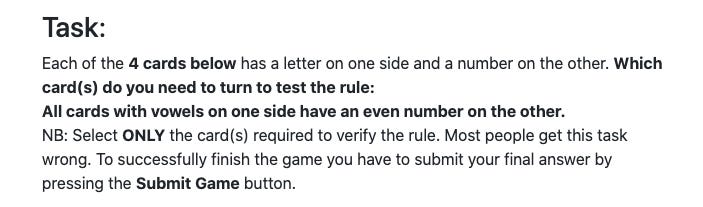
And an example set of cards:
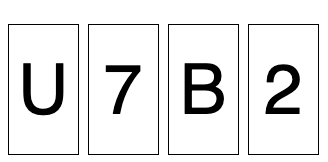
The particular letters and numbers, and their order, can be varied each time, allowing us to test whether people have properly understood the solution, rather than just recognising the answer in one instance.
Here is the general solution. The rule is of the form “if vowel then even number”, and you are looking at cards which are vowel, not vowel, even, not odd. Therefore the correct cards to inspect are vowel and odd. Only turning these cards is a good test of whether the rule is being broken - i.e. only these can potentially falsify the rule. It doesn’t matter what the not vowel card has on the other side (the rule is silent on this), and, similarly, it doesn’t matter what the even card has on the other side (the rule is also silent on this - it doesn’t say that evens have to come from vowels, just that vowels must lead to evens. The logic is the same as saying that all dogs have four legs doesn’t imply that all four legged animals are dogs).
So, in this example, the correct answer is to inspect U and 7.
The magic of this task is threefold.
First, most people get it wrong. They select U and 2, most likely, or variations (just U, all four cards). One idea about why is that we are driven by confirmation bias, intuitively drawn to inspect the cards which can confirm (vowel and even), rather than falsify the rule (vowel and odd). The idea that some ingrained aspect of our psychology drives this is supported by follow up experiments. Keeping the abstract form of the task - with letters and numbers - it is really hard to improve people’s chances. Changes of wording don’t seem to help much (the task had “a long record of resistance to facilitation”, even 30 years ago; Platt & Griggs, 1993), nor do significant financial incentives (Enke et al, 2021), nor does professional training (judges, lawyers and doctors all fail at about the same rate as the general public; Rachlinski & Wistrich, 2017).
The second piece of magic about this task is that people understand the correct answer when it is explained to them. This makes it different from famous teasers like the monty hall problem or those visual illusions where you know the underlying reality but you still can’t help perceiving the illusion (they are ‘cognitive inpenetrable’ Pylyshyn,1999). With the Wason Task, people may not realise the correct answer on their own, but they recognise it when it is explained to them.
The third piece of magic stems from the first two. Small group discussions convert majority failure to majority success on the Wason Task. Out of five individuals we expect 80-90% failure, meaning probably only one out of five gets the right answer. Put those five individuals in a group and motivated them to discuss the task for five minutes and we expect 80% success. This is probably in the form of them all agreeing on a single, correct, answer, but across many groups this gives an average of four of out five people reaching the right answer - a complete reversal of the solo reasoning situation.
An interactionist account of reasoning
The story I’ve told so far follows that given by Mercier & Sperber (2011, 2017) in their argumentative theory of reason. Their big idea, briefly, is that human reason evolved to convince others (and be skeptical of other’s attempts to convince you). This, they say, explains why we have blinds spots like confirmation bias, which lead to some dramatic failures as individual, isolated, reasoners. Reason, their account says, works through argument and interaction between individuals, and in this context individual biases can become strengths. So, confirmation bias, which may lead an individual, isolated, reasoner astray, allows an arguer to build the strongest possible case, and if they are mistaken there is always someone with the opposite view is who trying to do the same to disprove them. The result is a successful community of reasoners.
The Wason Task, and the performance of groups, plays a key role in their account. The power of small group discussions has been replicated multiple times, both with the Wason Task (Maciejovsky et al, 2013; Moshman & Gell, 1998; Augustinova, 2008; Maciejovsky & Budescu, 2007) and with other tasks (e.g. Woolley et al, 2015; Horowitz et al, 2021). There is a lot of variation in this literature depending on how groups are set up and which tasks they do. Larson (2009), argues that the most common outcome is for groups to improve the chances of those least likely get the right answer, but to - typically - produce a collective decision which is slightly worst than the individual most likely to get the right answer would on their own). So the Wason is a bright spot, a task with the potential to throw light on the important alchemy of group discussion when it raises the performance of most individuals it the group.
But despite this wealth of prior research, we weren’t able to find any transcripts of discussions among groups as they solved the task. Previous research tended to use verbal discussions, which would require transcription, and even when this had happened, the data hadn’t been archived and/or the correction permissions not obtained to share the text of people’s discussions.
With full transcripts, we thought, we would be able to analysis the linguistic and discursive features which discriminate successful from unsuccessful discussions. Maybe, even design interventions which could facilitate successful discussion.
And that is how the current work was born.
DialogueDen, DeliData…
We decided to run these experiments online, using text chat. That turns out to have been a lucky covid-secure decision, but it also means our results are directly applicable to many forms on online discussion - from family WhatsApp discussions to arguments in the comments section on a YouTube video. A bonus side-effect is that we don’t have to pay for transcription, since the discussion is typed, not spoken out loud.
To do this, we needed to be able to recruit people via an online recruitment platform, explain the task to them, sort them into groups, give them stable but anonymous identities, and let them discuss the task.
Georgi build a platform to do all this: DialogueDen (which he will release open source shortly). It shouldn’t be understated how impressive this is, and definitely encourages me to collaborate with people in computer science more often!
Then - easier said than done - Georgi recruited 1579 participants who participated in 500 separate group dialogues, making 14,003 utterances. The groups varied in size between 2 and 5, with an average group size of 3 (it is somewhat hard to control group size, since online participants can join and/or drop out at the last minute). Each participant was randomly assigned the name of an animal during the discussion, so a typical discussion looks like this:

In mundane exchanges like these, we can see the magic of deliberative reasoning beginning to work.
The headline results show that the power of group discussion holds, even for online discussions of strangers, and even for groups which are a bit smaller than typical. We asked participants, as individuals, what they thought the answer was before entering the discussion, so we had a measure of initial success. This confirmed that the Wason Task still confounds people: only 11% of people got it right. After a brief group discussion we asked people to submit answers again (every individual could submit independent answers). Now 33% of people got the right answer, which is a lot less than the majority success reported for face-to-face groups given time for an extended discussion, but still a 3x improvement.
Groups tended to agree in their final answer. Among those groups which settled on the correct answer, around half had no members who had initially selected the correct answer - a tantalising suggestion of the power of discussion to do more than merely spread the correct answer, but also to actually help groups come to novel insights.
Here’s another sample from the dataset:
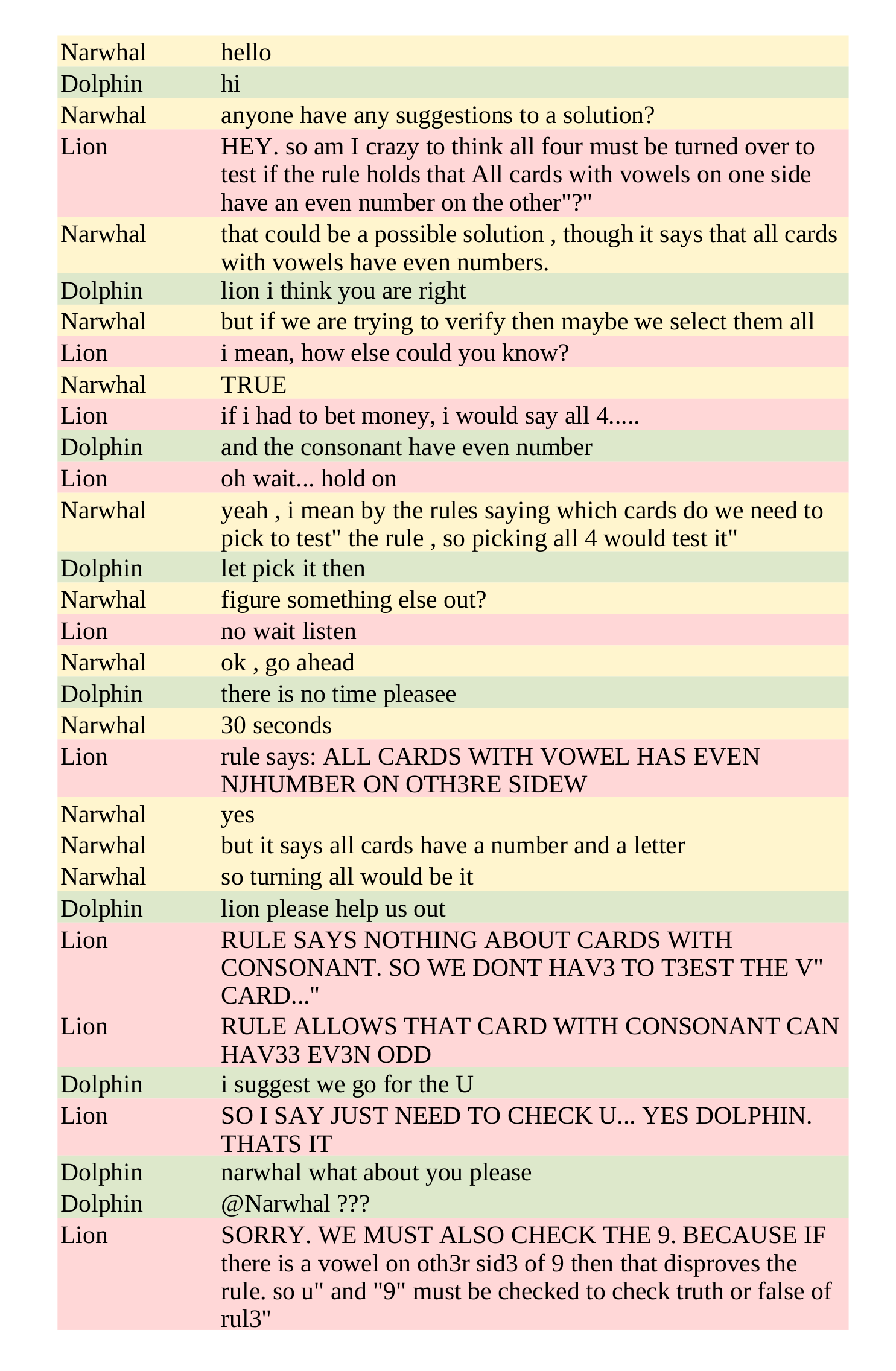
They get there, but only just!
Here’s another one. I’ve lightly edited it to remove a few conversational turns, but otherwise it is the complete dialogue. Note that they begin with two wrong suggestions for the answer:
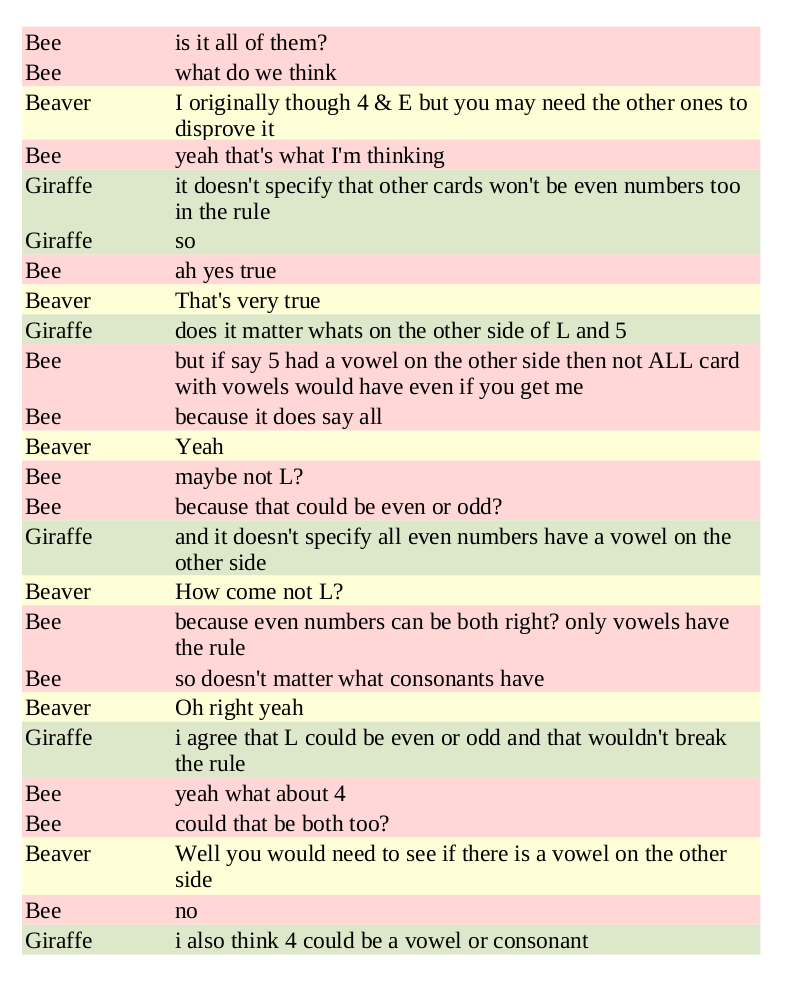
Halfway through, and they’re still working through the possibilities. It looks like it could go either way, but then…
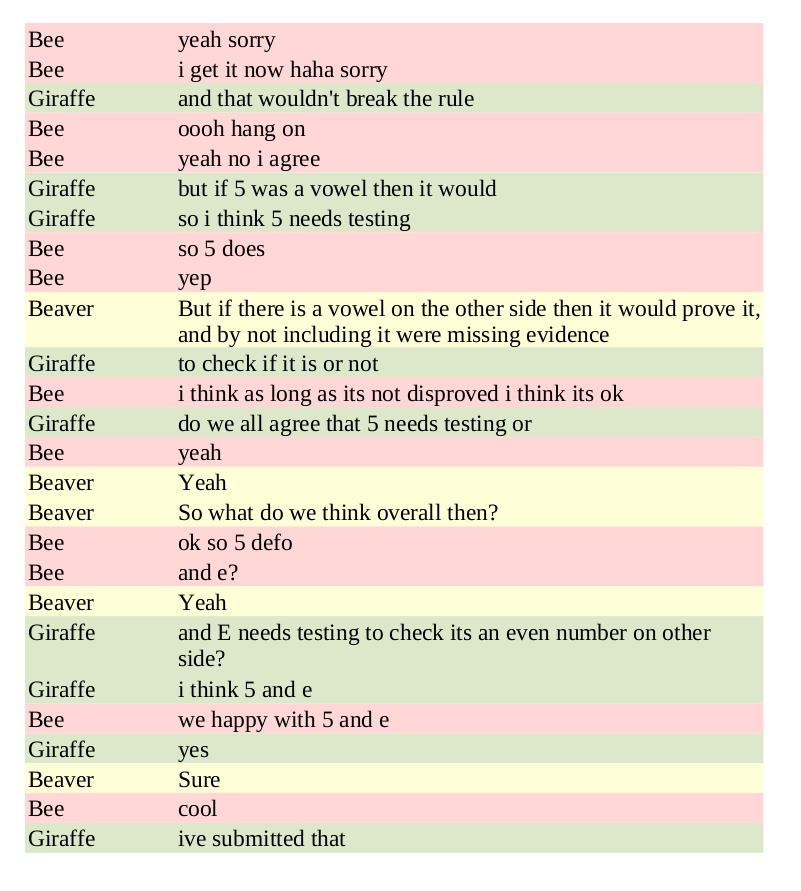
The whole dialogue is less than 50 turns long. We know from decades of research that people find the task famously hard. These are strangers. Five minutes ago they didn’t know each other and were doing something else, in five minutes they’ll be doing something else again. But here, now, they form a group and set their minds to correctly discovering the solution.
I love that, through the dialogues, you can experience yourself the moment of realisation - an individual and collective experience when the right answer comes into view. It is a like a microscope for human reasoning, allowing us to capture under glass that precise moment between a question, or a comment, or just a hesitation, and the new insight that allows people to leap for the correct answer.
…A DeliBot?
The paper describing how we did this work links to the dataset of 500 dialogues, and also describes an annotation scheme we have used. One longer term ambition is to analyse the dialogues to see what kind of utterances predict successfully realising the right answer.
Another ambition is that we can use the texts of the discussions as training data for a “dialogue agent” (i.e. chatbot) which would be able to take part in and moderate group discussions to make them more productive. Maybe, even, this would work for other tasks - tasks where there isn’t a logically correct answer, or if there is such an answer it isn’t as clearly demonstrable as in the Wason Task.
There’s lots more to do, and some of it we’re even doing, so I hope to report more results soon. Meanwhile please check out the paper and dataset, and get in touch if you’ve any ideas of ways of extending the project, or of using the data, or if you’ve any questions.
Reference
Karadzhov, G., Stafford, T., & Vlachos, A. (2021). DeliData: A dataset for deliberation in multi-party problem solving. arXiv preprint arXiv:2108.05271.
Project website: delibot.xyz
Abstract:
Dialogue systems research is traditionally focused on dialogues between two interlocutors, largely ignoring group conversations. Moreover, most previous research is focused either on task-oriented dialogue (e.g.\ restaurant bookings) or user engagement (chatbots), while research on systems for collaborative dialogues is an under-explored area. To this end, we introduce the first publicly available dataset containing collaborative conversations on solving a cognitive task, consisting of 500 group dialogues and 14k utterances. Furthermore, we propose a novel annotation schema that captures deliberation cues and release 50 dialogues annotated with it. Finally, we demonstrate the usefulness of the annotated data in training classifiers to predict the constructiveness of a conversation. The data collection platform, dataset and annotated corpus are publicly available at https://delibot.xyz
Use the button to sign up for future newsletters on the topic of reasoning, argument and decision making. Unlike here, this is mostly NOT directly about my own research projects.
Very interesting!
Is there any work in more open decision making domains?
I wonder how we might use our Google Doc conversations in a more effective way.