
Grok, a mixed bag
Quick notes on Grok/Grokipedia and LLMs for fact-checking

Last time, I made the claim/ shared the worry that AI may erode the very knowledge-generating infrastructure it relies on (to produce training data). As if to illustrate this, I came across this blunder from Grokipedia, the AI curated ‘anti-woke’ encyclopedia project from Elon Musk: Grokipedia misreports the death of one of the foundational researchers in NLP, Kenneth Church.
I’m reliably informed that Prof. Church takes in good humour this declaration by one of the products of the field he helped define. Nonetheless, there’s definitely some kind of Frankenstein’s monster stuff going on here.
Here’s the page, and here’s a screenshot in case it changes:
![Fact-checked by Grok 2 weeks ago
Kenneth Church
Kenneth Ward Church is an American computer scientist renowned for his pioneering contributions to natural language processing (NLP), information retrieval, artificial intelligence (AI), and machine learning, particularly through work with large-scale corpora and language models.[1][2] He earned his BS in 1978, MS in 1980, and PhD in 1983, all in computer science from the Massachusetts Institute of Technology (MIT).[2]
Sidebar includes "Death and legacy"](https://substackcdn.com/image/fetch/$s_!JIPg!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F08e4a6cc-9077-4afd-8ed0-8a14920fef5b_1272x534.png "Fact-checked by Grok 2 weeks ago
Kenneth Church
Kenneth Ward Church is an American computer scientist renowned for his pioneering contributions to natural language processing (NLP), information retrieval, artificial intelligence (AI), and machine learning, particularly through work with large-scale corpora and language models.[1][2] He earned his BS in 1978, MS in 1980, and PhD in 1983, all in computer science from the Massachusetts Institute of Technology (MIT).[2]
Sidebar includes \"Death and legacy\"")
“Fact-checked by Grok 2 weeks ago”
![Death and Legacy
Final Years and Passing
In his later years, Kenneth Church resided in a retirement facility in Reno, Nevada, where he lived with family following his move there in the late 1990s.[7][10] He maintained a connection to horse racing through his longstanding role as an ambassador for the Del Mar Thoroughbred Club, which he held into the 2010s, occasionally participating in events and sharing his expertise with enthusiasts.[10]
In early July 2020, Church was diagnosed with pneumonia at his Reno facility and transferred to a hospital, where he tested positive for COVID-19.[7] He died on July 13, 2020, at the age of 90, from complications related to the virus and pneumonia.[7][10] Church was preceded in death by his wife of 63 years, Nancy, and is survived by two daughters, Debbie Anderson and Laurie Kurluk, and a son, Michael; the family requested no services.[7]](https://substackcdn.com/image/fetch/$s_!jK3X!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fa01a0b8d-9faa-46e8-8652-d4fd63d66a07_1280x889.png "Death and Legacy
Final Years and Passing
In his later years, Kenneth Church resided in a retirement facility in Reno, Nevada, where he lived with family following his move there in the late 1990s.[7][10] He maintained a connection to horse racing through his longstanding role as an ambassador for the Del Mar Thoroughbred Club, which he held into the 2010s, occasionally participating in events and sharing his expertise with enthusiasts.[10]
In early July 2020, Church was diagnosed with pneumonia at his Reno facility and transferred to a hospital, where he tested positive for COVID-19.[7] He died on July 13, 2020, at the age of 90, from complications related to the virus and pneumonia.[7][10] Church was preceded in death by his wife of 63 years, Nancy, and is survived by two daughters, Debbie Anderson and Laurie Kurluk, and a son, Michael; the family requested no services.[7]")
If you read the whole article, it is clear that it conflates two individuals, one of whom may actually have died of COVID-19 in 2020. So you get this bizarre piece about a famous jockey who retired from horse-riding and took up a prestigious research career at Bell Labs.
I’m interested if the article gets corrected, because there doesn’t seem to be an obvious way to do this yourself (or even request a correction). When I first viewed the page there was an EDIT button which invited you to log in, but when I did the button disappeared!
Wikipedia is better not just because it is more correct about Kenneth Church, but because it contains a mechanism for correction, and a community behind it to provide that correction. Many errors on Wikipedia are corrected in minutes, especially any that draw significant attention.
Grokipedia may be right or wrong, but when it is wrong it isn’t clear how it can be corrected to be right. And that, ultimately, is why I’ll go on trusting Wikipedia more.
Interestingly, Grok (the chatbot) can spot the error on Grokipedia. When I prompted it, it replied
“Grokipedia (being the AI-generated, “fact-checked by Grok” alternative encyclopedia) has simply smashed their two biographies together under a single page title with no disambiguation, no warning, and no attempt to separate them.
I love that even Grok puts “fact-checked by Grok” in scare quotes.
This also illustrates something fundamental about AI - it does not have any shame, nor, it seems, the same need for coherence in beliefs that humans do. Rightly or wrongly we try to strive for consistency with ourselves. AI will happily contradict itself from moment to moment (or even sometimes in the same sentence).
Here’s a great example from Ian Leslie. The same query, just phrased differently, gets completely opposite opening responses:
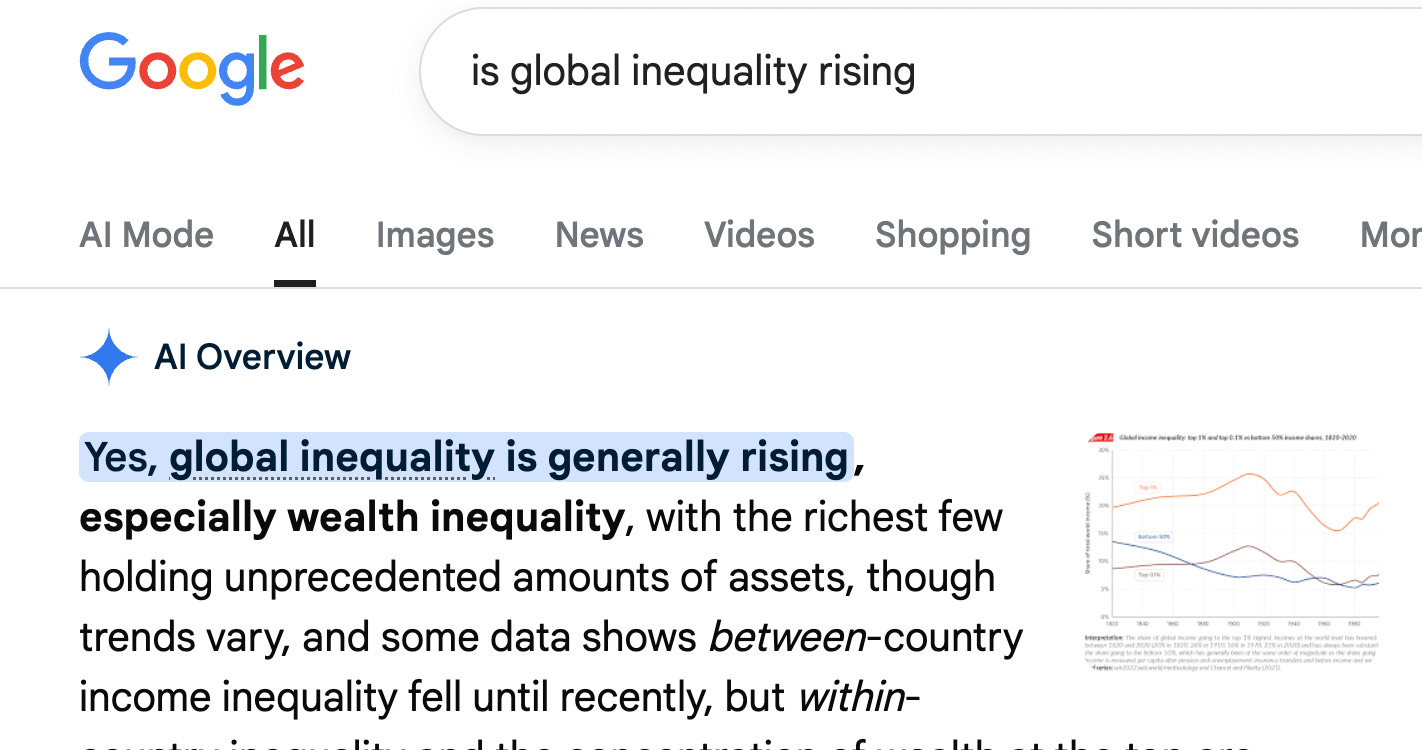
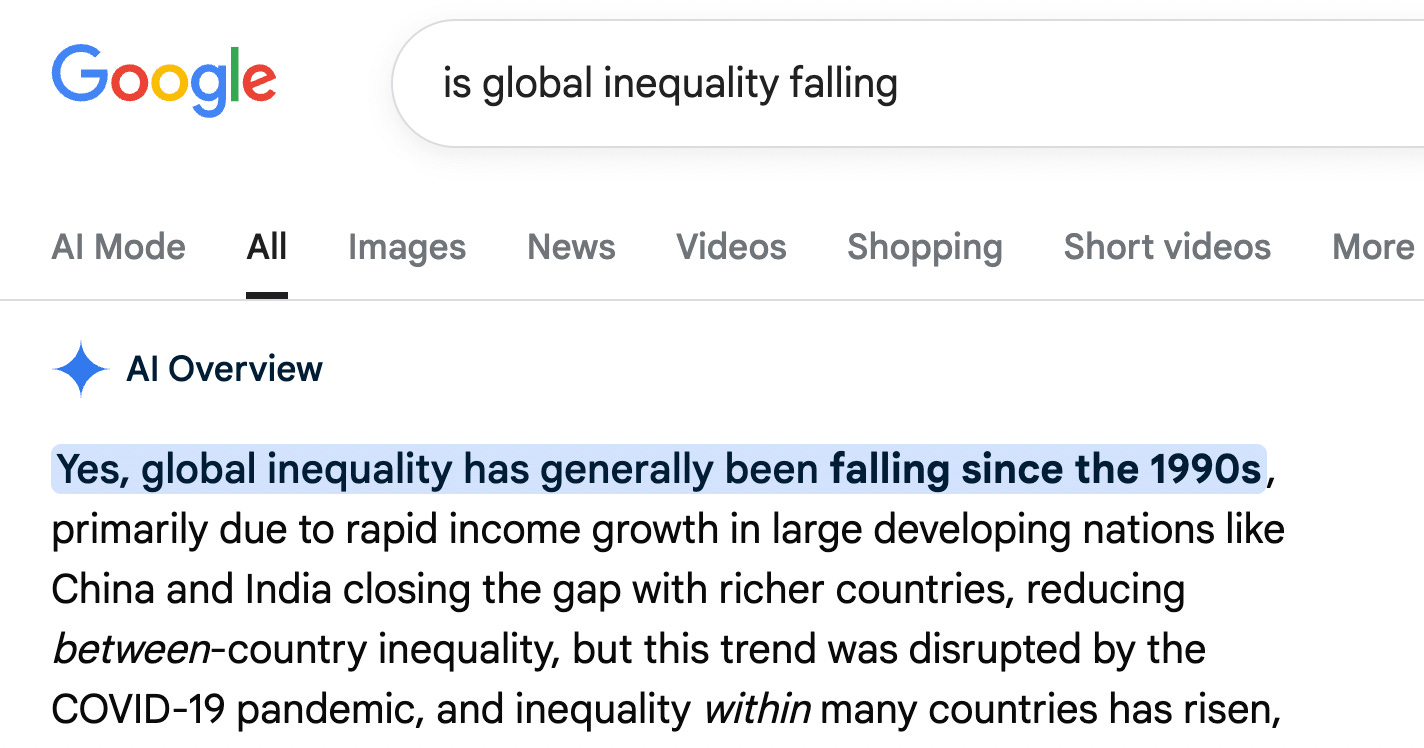
Now obviously consistency may be overrated, and humans are vulnerable to these kinds of manipulation by the way questions are phrased too. Is it, however, too fanciful to think that our self-respect and sense of shame prevents us leaning into them to the same degree?
If we carry over our intuition for human minds, that there is some ‘self’ there in the AI which we can talk to, discover the truth about, correct and/ or shame into better behaviour we’ll be misled. There’s no There, there. The AI is an alien mind which has weird edges. Treat with caution.
PREPRINT: @Grok Is This True? LLM-Powered Fact-Checking on Social Media
This said, it looks like people like Grok, on X, and about 5% of its use is for fact-checking. They like it so much it is drawing energy away from the Community Notes moderation system:
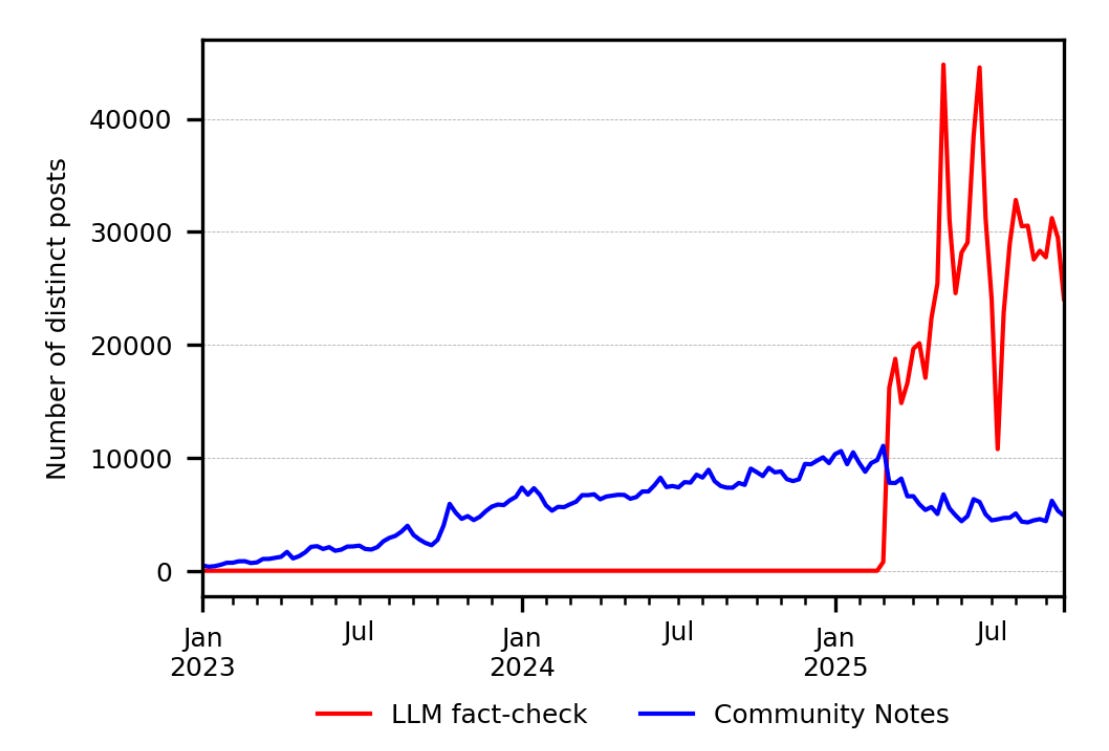
Link: @Grok Is This True? LLM-Powered Fact-Checking on Social Media (2025), T. Renault, M. Mosleh and D. Rand
There’s a lot more to say about LLMs for fact-checking, but the popularity of Grok illustrates both a strength (people like interacting with AI via natural language), and a weakness (AI can eat alternative systems for producing knowledge).
Dylan Matthews: Pro-social media
Matthews makes the case that a) people mostly use LLMs for fact-checking b) LLMs have a tendency to non-customised responses. The upshot:
My provisional theory is that LLMs, as a consumer product, will push people’s senses of reality closer together in a sort of mirror image of the way social media has fractured them. They are not algorithms meant to custom-tailor content (including facts) to you, and what you will find infuriating or motivating. They are centralized systems that, until you prompt them or give them context, behave basically the same way for everyone.
Matthews illustrates his case with Grok’s response to queries about the Renée Good shooting, which quickly became highly polarised. Grok, despite its engineering, didn’t lean towards the right-wing interpretation.
The idea is supported by the Renault, Mosleh and Rand preprint (above). This shows that Republicans used Grok slightly more than Democrats, but when they do it is more often to check Republican posts than Democratic posts. Supporting Matthews’ hypothesis of LLMs-as-consensus-machine, Republican posts were more likely than Democratic posts to be rated false by Grok, and Grok tended to agree with another AI model (Perplexity), with Community Notes and with professional fact-checkers.
Consensus on facts!
The big surprise of LLMs may be that the inertial force of all the text they are trained on produces a conservative, consensus-orientated, force. Not quite the truth, but definitively truth-adjacent, and a long way from the ‘pick your own’ facts nightmare many people fear the digital age will bring.
Link: Pro-social media
This newsletter is free for everyone to read and always will be. To support my writing you can upgrade to a paid subscription (more on why here)
Keep reading for more research on AI and social media
PREPRINT: Industry Influence in High-Profile Social Media Research
From the abstract:
Leveraging openly available data, we show that half of the research published in top journals has disclosable ties to industry in the form of prior funding, collaboration, or employment. However, the majority of these ties go undisclosed in the published research… we find evidence that industry ties are associated with a topical focus away from impacts of platform-scale features.
Covered by Kai Kupferschmidt in Science: Nearly a third of social media research has undisclosed ties to industry, preprint claims
Link: Industry Influence in High-Profile Social Media Research
PREPRINT: Fact-Checking and Misinformation: Evidence from the Market Leader
Fact-checking on Meta works - less circulation of false information, posts fact-checked as false more likely to be deleted, and those fact-checked less likely to post false information in the future.
Read all about it in the essential write up found in Indicator: An 18-month study found that fact-checking on Facebook reduced engagement with false info
PREPRINT: When” Likers’‘Go Private: Engagement With Reputationally Risky Content on X
This is a surprising result, which uses a nice study design (difference in difference, for strong causal inference fans).
In 2024, the X platform changed so that “Likes” were private. Prior to this, anyone who could view your account could inspect which posts you’d Liked (resulting in some very small-minded cancellation adjacent behaviour, in my opinion). This study compared “high reputational risk” accounts (extremists, politicians, OnlyFans) with “low reputational risk” accounts (actors, singers, tech influencers), and showed there was no discernible change in how many Likes their posts received before and after the change.
This is obviously contrary to the prediction that social concerns - including risk of shaming - drive a lot of social media behaviour. The study also includes a survey in which X users report that whether their Likes were public would indeed change their behaviour. So the result is all the more surprising.
The failure to detect a difference doesn’t mean that some users didn’t change their behaviour, as the authors discuss. It might be that most Likes are driven by bots, which are immune to shame, but I think the study design is strong and we should note when our expectations are contradicted.

Chuai, Y., Ribeiro, M. H., Lenzini, G., & Pröllochs, N. (2026). When” Likers’‘Go Private: Engagement With Reputationally Risky Content on X. arXiv preprint arXiv:2601.11140.
PREPRINT: Natural language communication enables groups to overcome unrepresentative private evidence
Nicely framed experiment, showing that allowing people to talk - rather than just report what they see via a number - allowed more effective group performance. In particular, “private evidence” is what each person knows individually, and which a successful group needs to combine across individuals to access the benefits of being in a group. Prior research shows that groups tend to under-share private knowledge (preferring to discuss common knowledge) leading them to forego the “gains from trade” of pooling the different information available across all group members.
By contrasting natural language communication in a tight, controlled, way with communication via a slider scale, this experiment shows the communicative information we are able to pack into even the briefest natural language communications (compare for example the way you would interpret differently “It’s 73” versus “I think it is 73”).
Of course, this caught my eye because LLMs promise to take advantage of the finely honed communications channel of natural language.
From the abstract:
Here we test the epistemic conditions under which language may help or hinder collective inference. In two experiments (N = 2,249), networks of four participants observed private samples from an underlying probability distribution and communicated over repeated rounds to estimate that distribution. We manipulated communication channel (natural language vs. numerical belief reports) and systematically varied the quality of private information: total sample size, representativeness of individual samples, and how evenly information was distributed across participants. All groups improved through social interaction, but groups restricted to numerical transmission performed systematically worse. Critically, the advantage of language emerged specifically when private samples were unrepresentative of the underlying truth, precisely when learners must appropriately weight others’ evidence against their own. Analysis of message content revealed that this benefit arose from participants’ ability to relay information across the network, extending the reach of evidence beyond direct dyadic exchange
Zubak, Y., & Hawkins, R. (2026, January 16). Natural language communication enables groups to overcome unrepresentative private evidence. Retrieved from osf.io/preprints/psyarxiv/mp2yf_v1
…And finally
RIP Hajime Ouchi 1945-2024, originator of the Ouchi Illusion

It works particularly well as you scroll past, I notice, so I hope everyone reading on mobile enjoys.
Ouchi’s death was announced last week to the vision science community by Lothar Spillmann on the cvnet listserv
More on the illusion from Spillmann: https://doi.org/10.1068/p7384
For an accessible introduction, it’s discussed in Chapter 30 of Mind Hacks https://mindhacks.com/book/
END
Comments? Feedback? Requests for topics to write about? I am tom@idiolect.org.uk and on Mastodon at @tomstafford@mastodon.online
Regarding the topic of the article, it's insightful how this Grokipedia blunder makes one wonder about the subtle ways AI can miror our biases, not just generate new errors.