


Epistemic agents
Reasonable People #26: An early vision of the internet, and the social media that might have been

In Knowledge In A Social World (1999), Alvin Goldman gives an account of knowledge which is both truth seeking and social. The “truth seeking” part needs to be explicit, according to Goldman, as a defence against fashionable post-modernisms which deny the existence of truth and pretend to build an account of knowledge based on some other feature, such as consensus.
In the section on how technology might alter communication, Goldman allows himself to speculate about a future of human cognition interacting with computer intelligences.
To assist with such problems, a major initiative in the information access industry is the creation of autonomous agents, computational entities that cooperate with a user in the service of information-gathering tasks. The metaphor used is that of a personal assistant who helps a user get the job done and typically hides the complexity of its execution
As well as being an interesting idea, it allows us a glimpse how the information technology looked in the earlier days of the internet:
For example, to assist in a search task on the Web, one might use an interface agent such as “Scatter/Gather,” developed by Marti Hearst and colleagues. Scatter/Gather creates a table of contents that changes as the user gets a better understanding of what documents are available and most likely to be relevant (Hearst 1997). Suppose that Aunt Alice uses Excite and retrieves the first 500 Web pages it suggests. The Scatter/Gather system can analyze those pages and divide them into clusters based on their similarity to one another. Aunt Alice can scan each cluster and select those that appear most relevant. If she decides she likes a cluster of 293 texts summarized by “bulb,” “soil,” and “gardener,” she can run them through Scatter/Gather again, rescattering them into more specific clusters. After several iterations, this can whittle down the set of pages to a few dozen, a more tractable number. In this fashion, refinements in search procedures can make a significant difference to knowledge quests. Another such intermediary agent is EchoSearch, which fires up parallel searches of about eight search engines, picks the “best” ten of their results, and summarizes and indexes them.
Can you even name eight search engines? Can you remember the last time you ‘retrieved the first 500 web pages’ from a search? If so, you probably used the internet in 1999 when this was published.
This passage shows just how far Goldman’s vision of epistemic agents has mutated. His writing seems to suggest we are at the beginning of a Cambrian explosion in the number and type of possible epistemic agents, but from the vantage of 2022, we can see that this diversity never materalised. We don’t invoke Scatter/Gathere, or deliberately deploy Intermediate Agent to aggregate and select the best. On the modern interent, except when we search, we hardly think at all of ourselves using epistemic agents at all. These tools are part of the internet fossil record, and perhaps even extinct lineages rather than the primeveal ancestors of a whole zoo of diverse epistemic agents.

Delegation of tasks on our knowledge quests hasn’t gone away. Instead, epistemic agents are now deeply encapsulated in the sites and apps we use. Companies design and deploy the epistemic agents and we buy their services, based on them “just working” - in other words, accurately guessing what will make us happy. So Spotify makes a mix which is a pleasing blend of songs I already know and like and new songs which I have a good chance of liking. Amazon suggests products I might like to buy in combination with my current purchase. And Google, ah Google, the one search engine most of us only ever use, and mostly only look at the very first result too.
Along with this encapsulation, it seems like one epistemic agent ate all the others - recommendation. Whether it is new music, concurrent purchases, or which the best take-away is in my area, most epistemic tasks can be looked at as recommendations. Recommendation algorithms have their own wikipedia page, their own academic conference. If there are sibling areas for other epistemic tasks, they aren’t immediately obvious (at least to me. Maybe data mining? Maybe filtering?).
One further thing - recommendation algorithms have themselves been eaten, by social information. It seems so obvious, you need the standpoint of Goldman’s text to glimpse it, but it isn’t inevitable that all recommendations would work by aggregating and filtering the information from a distributed social network of users. Spotify recommends tracks liked by people who liked the things you liked, amazon uses information from previous shoppers. Google uses the pages linked by other pages. That’s why they won - they didn’t try and define page quality independently, based on some objective rating system. They took signals from the network of users (people who build webpages, and now, also, people who search for webpages). From Goldman’s stance, this is a heresy - because it abandons the attempt to seek an independent truth - but it is a heresy that manifests works.
* * *
Pandemonium is another model of social intelligence. An early and influential model of computation, proposed by Oliver Selfridge in 1959. The pandemonium model assumes that problems can be solved by a legion of specialised demons. Each demon, like their underworld counterparts, has a very specialised task. In hell, a particular demon might be responsible for stoking the fires at the feet of a particular sinner. In Pandemonium, if the problem is word reading, a particular demon might be responsible for recognising the letter A, and another responsible for recognising the letter R. Each demon shrieks, with a volume related to their confidence about what they’re seeing. At the top sits a decision demon whose job is to judge the loudness of shrieks. In this way, via interactive connections, the myopic and stupid demons generate an emergent solution to the greater task
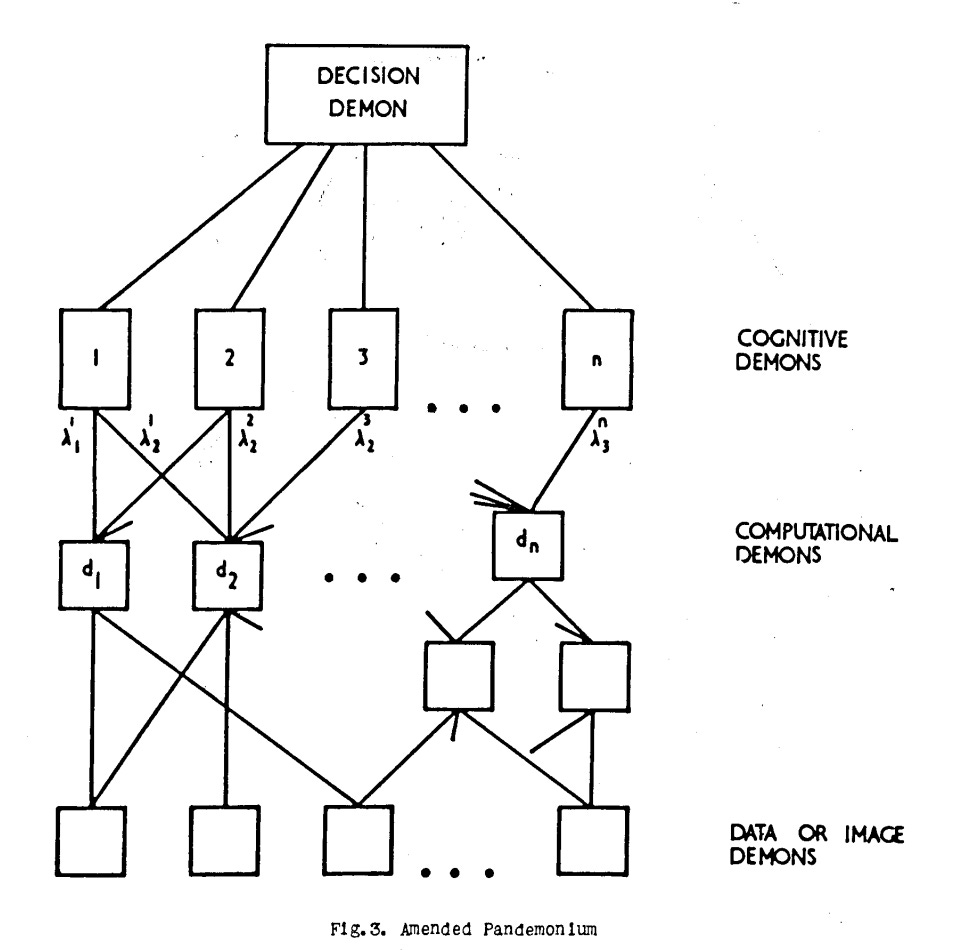
Crucially, also, the whole inferno, adapts and evolves as shrieking demons bud, split and dissolve according to how useful their shrieks are.
The illustrations by Leanne Hinton in a 1972 textbook (Lindsay & Norman, Human Information Processing) cemented Pandemonium in the imagination of a generation of cognitive scientists. You can see why:

This model is an ancestor of modern neural networks, of deep learning and all that hoo-har. The methods for the model to self-adapt have progressed so much that we can now solve tasks without us having any idea of how they are solved. Finding out the function and identity of the individual demons involved requires a Dante-esque quest.
The success of neural networks underscores the power of the social model of intelligence, but again betrays the instinct of Goldman’s account. The agents here are faceless subprocesses, born in unlit pits by blind algorithm. The intelligence is collective, but not deliberate, without identification of distinct intentions or tools which are wielded by a central controller.
* * *
"Hell is Empty, and All the Devils are Here"
- The Tempest, Ariel, Act I, Scene 2.
Recommendation ate all other agents, and social ate all other methods of doing recommendation, then a handful of platforms ate - or are trying to eat - all possible tasks. Meta/Facebook’s ambitions for a metaverse are just them saying the silent part out loud - all the other platforms have the same aspiration, to become walled gardens in which you never have to leave and all your business (all your attention, all your interactions) happen via them.
Reversing the original thought, what happens if we look at these networks - ostensibly social media - as epistemic agents? Twitter, facebook, tiktok, youtube etc all do epistemic work, although they may masquerade merely as ways of keeping in touch or entertaining. Their recommendation algorithms drive you to particular kinds of content (possibly driving polarisation), their affordance drive particular kinds of interactions (read C. Thi Nguyen on how Twitter prioritises false intimacy, and then punishment as your in-crowd comments get taken out of context).
The recommendation algorithms in these platforms are great at showing me more of what I like, but are there any which try and identify gaps in my experience and surprise me? The algorithms are great for promoting affiliation, suggesting people I might know, but are there any which deliberately try and open new vistas in my social network, rather than merely complete triadic closure? A few platforms offer fact checks when I start posting about controversial topics, but is there a search engine which specialises in presenting me with information which contradicts the assumptions driving my current searches? The retweet function acts to rip statements out of context, but where is the function which encourages accountability, joining up what you I’m saying now with what I said previously?
You’ll say - Tom, the flaw here isn’t the algorithms, it is human nature. We get more of what we like because we’re fundamentally habit driven creatures who seek familiarity. There’s a truth to that, but Goldman and the 1990s fad for agents inspires an alternative vision of the internet: not one where we have devolved our agency to the social network and colossal platforms, but one where we retain more intention in how we cultivate our knowledge and experience of the world, where we design bespoke, named, agents, to carry out epistemic tasks. And maybe end up knowing more, or better, or different.
* * *
Goldman, A. I. (1999). Knowledge in a social world. Oxford University Press.
O. G. Selfridge. "Pandemonium: A paradigm for learning." In D. V. Blake and A. M. Uttley, editors, Proceedings of the Symposium on Mechanisation of Thought Processes, pages 511–529, London, 1959.
Lindsay, P. H., & Norman, D. A. (1977). Human information processing: An introduction to psychology. Academic press.
Other stuff …
Paper: Agents that reduce work and information overload (Maes, 1995)
A citation classic from the Cambrian era of epistemic agents. Although it does mention the use of other users to inform agents, the focus is squarely on the individual user training their individual agent - a figure-ground reversal of the situation with today’s apps. Did we all overestimate how different we are from each other?
Here, for the record, are Maes’ 4 example agents:
Entertainment Selection Agent
News Filtering Agent
Meeting Scheduling Agent
Electronic Mail Agent
Three of these are ubiquitous. Where is my jetpack meeting scheduling agent?
Agents seem to have been the Next Big Thing in computer science in the late nineties. Witness
Caglayan, A., & Harrison, C. (1997). Agent sourcebook. John Wiley & Sons, Inc..
Wooldridge, M., & Jennings, N. R. (1995). Intelligent agents: Theory and practice. The knowledge engineering review, 10(2), 115-152.
News: The life and tragic death of John Eyers
I’m quoted in this Guardian piece by Sirin Kale The life and tragic death of John Eyers – a fitness fanatic who refused the vaccine, part of their Lost To The Virus series.
(After the interview Kale did with me I felt like I was massively more articulate and well informed than I normally am. It took me about ten minutes to realise this was a side-effect of dealing with a skilled interviewer)
One quote:
In the age of social media, we don’t even need to have met the people we trust as much as established experts. “That’s why social media is so dangerous,” says Stafford. “Because people share that emotional connection with influencers they might never have met. But it’s an asymmetrical intimacy. I may think I know that vlogger and they are talking to me. But really they’re talking to millions of people – and the advertisers generating them their revenue.”
That quote jumps off from our work looking at the interaction of values, trust and expertise. The paradox, which isn’t explored in the Guardian piece, is that John Eyers should have trusted his friends and family, who wanted him to get vaccinated just like the scientific experts, but instead he ignored both groups in favour of social media anti-vaccine sentiment. My argument - that to listen to scientific advice we need to trust the values of those communicating risk - is silent on why this might be. Perhaps the urge to construct our own beliefs, and clinging to them because they are idiosyncratically ours, is part of the explanation. Another part may be the particular blend of social and epistemic goods that online interactions are tuned to provide : asymmetric intimacy, an endless chain of new but confirmatory information, and demonised outgroups (as well as - bonus! - the chance to interact with some of the most unhinged and angry representatives of those outgroups, and/or bots pretending to be them).
PODCAST: What we can learn about dialogue, persuasion, and change from those who have turned away from extremism
David McRaney has become this incredible resource on misinformation, mind change and belief. No doubt recording the 200+ episodes of the podcast helped. This episode with Megan Phelps Roper, who talks about her own conversion away from an extreme religious group the Westboro Baptist Church, is great place to start, or catch up:
Finally…
xkcd nails, again, something fundamental about how our knowledge affects how we see the world

Interesting piece! On the point about not bothering to look below the first few returns in SERPs, I have noticed that I do that too--but not because I crave only conventional wisdom or the most popular opinions, it's because the *relevance* of information seems to fall off so steeply. SERP Page 3 is not full of unusual opinions about X; rather, it is not even about X at all. I am not entirely sure why Goog search outputs have this property, but it might suggest guarded optimism about market for alternatives or improvements.
A nice 2022 rejoinder on the Web 1.0/2.0/social media question whether the Internet is or can be a serendipity engine (https://www.bbc.co.uk/programmes/b039d4b4).
A subset of AI/ML research in recommender systems and esp. computational creativity builds algos to reliably generate/find surprising information: novelty search, outlier detection, etc. Some startups have cropped up that want to address the issue you point out and use such algos to insert diversity into people's info consumption, but they have remained niche/artsy projects (like, *really* niche, not just DuckDuckGo niche), or turned recommender system – e.g. Foursquare was conceived as an urban serendipity engine by Dennis Crowley and has become a hipster brunch recommender system.
I think broad-spectrum newspapers and (used) bookstores remain the serendipity epistemic agents in my agent zoo. But your post triggered in me – in good old Web 1.0 associative style – memories of two related posts by Clive Thompson: https://uxdesign.cc/rewilding-your-attention-d518ede18855 and https://onezero.medium.com/a-search-engine-designed-to-surprise-you-b81944ed5c06.