
It's in the training data
Essentials for understanding the new AI models, continued

Previously I wrote about how large language models launder human knowledge to produce the illusion of intelligence. The speed and scale of the answers they can give trick us into thinking they have the competence, dedication and expertise of the human writers whose text they have absorbed, but it is a trick. It is a great trick, but because it is done in a different way from the way a human would learn, understand and then produce answers on a topic, it has surprising weaknesses as well as surprising strengths.
To properly understand this trick, you need to appreciate the sheer size of the training data used to produce large language models, and how much of it the models are actually storing directly (and perhaps reproducing in their answers).
The training data is big, really big
It’s hard to get definitive answers about the training of the current main models. What ChatGPT, Gemini and Claude and friends are trained on, and how they are trained, are commercial secrets. Google report this for their Gemini model :
“Our pre-training dataset uses data from web documents, books, and code, and includes image, audio, and video data.”
I wonder whose web documents, books and code Google used (Google’s mission: “to organise the world’s information”).
Anthropic report for the development of their Claude model that the types of data they use are:
“Publicly available information via the Internet
Datasets that we obtain under commercial agreements with third party businesses
Data that our users or crowd workers provide.”
We know ChatGPT 4 cost over $100 million to train, but - as with the others -we don’t know what they trained on. The suspicion is that it is everything on the internet - every DIY or recipe site, every forum, every news page - as well as the accumulated human thought in every book from every library that they could get their hands on.
The accumulated size of this training data is hard to comprehend. For GPT-3 (July 2020!) it was something like 499 billion tokens; a token is a unit used in language processing models, often a word or smaller. This makes the GPT-3 training data approx 693 GB (depending on how you store it), or something like 150 times the size of English-language Wikipedia (which is currently 7,038,356 articles and approximately 4.9 billion words), itself over 8,000 times longer than War and Peace (587,000 words).
Put another way, if you take 5 minutes to read a newsletter like this one, which is about 1500 words, it would take you approximately 4,500 years to read all of the GPT-3 training data (allowing no time for breaks, sleep, etc). That’s dozens of human lifetimes just to read, think how many lifetimes it took to write.
The training data was probably illegally obtained
Because the AI companies are cagey about how their built their models, information about the source data they use for training often only comes to light because of the court cases. Wired has an AI copyright case tracker (paywalled, you can see with a free trial), which documents dozens of lawsuits, all but one unresolved, against all the major AI companies and lodged by celebrity authors and media companies like Disney and The New York Times, amongst others.
The core legal debate turns on whether using copyright material to train an AI is “fair use”, something like the situations of parody, news reporting, or academic research where you can repeat material despite copyright. Part of the issue is that our historical copyright laws may not exactly fit the new technology of generative AI. AI models require the copyrighted material to be trained on, but then they - mostly - create new work without exactly and directly reproducing that material. (For more on this issue I recommend this talk at the Allen AI institute by James Grimmelman, Tessler Family Professor of Digital and Information Law Does Generative AI Infringe Copyright?)
Either way, it is clear that AI companies did not stop to ask permission in the race to assemble their training data. Anthropic, makers of Claude, are alleged to have pirated 7 million books, and popular opinion in AI circles is that this is typical AI-company behaviour, not an exception. Meta did the same, taking pirated books from sources like Library Genesis, a site well known to students and other lovers of free books.
The training data is in there and still accessible
The training data is used to produce the model weights - these define the associations that constitute the knowledge the model possesses. Much like you associate “Bacon and” with “Eggs”, so a large language model can associate your question with an answers that it provides as output. Along with some other settings these things make up the total “model parameters” which define how the model works, and which are the result you get for your tens or hundreds of millions of dollars spent in training.
The model parameters are meant to represent in compressed form the training data, extracting important generalisations. While the training data is large, the models themselves may also be surprisingly big.
GPT-3 was 175 billion parameters, GPT-4 was rumoured to be a thousand times larger. Meta’s LLaMA model comes in variants from 7 billion to 2 trillion parameters. Anthtropic and Google aren’t telling about their models.
The ratio of training data size to model parameter size shows how much compression the model has done to represent its training data. If GPT-3 was trained on 499 billion tokens, and learnt 175 billion tokens that’s only a compression ratio of just under 3.
What this means practicality is that the models may be learning abstract generalisations from their training data - the sort of thing that represents insight into a domain - but they may also be storing, verbatim, specific things they have been trained on.
So, for example, if a model can do brilliantly on exam set for high school students, should we be impressed? The paper announcing GPT-4 reports that up to 100% of the questions from exams it was tested on were in the training data. The same exam questions are studied and taken by hundreds of thousands of college students each year. If the model has slurped up billions of words of internet text, there’s a good chance it slurped up some answers too. And indeed, that’s the intent, my point is that we should calibrate how impressed we are at the answers given appropriately.
With something like a college exam answer it is hard to judge how close the model output is to something contained in the training data. But with the right prompts you can provoke models to produce output which exactly matches data they were trained on, even if that data is potentially sensitive. This means things like names, addresses, phone numbers (which might be in email signatures), or chunks of copyrighted text.
This xkcd cartoon nicely illustrates the principle.

The model has been trained to complete fragments of text. That means that it can “leak” parts of the original training data, and that can be a privacy problem (as well as underscoring the copyright issues).
Although AI companies can try and fix things by blocking the prompts most likely to leak information, this is a general problem with all language models, not a quirk of the particular models tested.
One recent report (Cooper et al, Extracting memorized pieces of (copyrighted) books from open-weight language models, May 2025) reports that some - but not all books - may be memorised by the big commercial models “almost entirely”. To quote:
Harry Potter is so memorized that, using a seed prompt consisting of just the first line of chapter 1, we can deterministically generate the entire book near-verbatim.
My own mundane experience of this was when I was using an AI copilot to help write the code for annotating a graph I’d made with my social media handle (“Made by @tomstafford”). The AI provided the code to add a social media handle as an annotation, but it autocompleted with someone else’s handle - a real user! And presumably someone who had at some point shared code online which did what I wanted, but for their handle.
As well as text and computer code, images which are in the training data can also be leaked by AI models. Here’s an image from Carlini et al 2023:

Conclusion
Because these models are so large, they have captured - in some cases exactly, as these examples show - huge amounts of human knowledge.
So, next time a large language model seems impossibly smart, remember just how much training data has gone into the model - and how many millions of uncredited hours of human intellect this represents. The seemingly brilliant output of the model may be a mash-up of multiple sources, or it may be a plausible generalisation over all relevant sources. Or it may even be a direct repetition of something already contained in the training data. It’s hard to know.
After the break, links on the normal topics of cognitive science, reasoning and persuasion.
Previously
This was part 3 of my summer writing hobby - things to help you think about AI. Catch up on parts 1 and 2:
Community Notes rely on ‘legacy media’
Despite attacks by the owner of X on legacy media, and the tilt towards relying the Community Notes system for content moderation, analysis by Bloomberg (Community Notes Can’t Save Social Media From Itself, 18 March 2025) shows that the Notes of Community Notes typically rely on traditional sources (media like the NY Times), professional fact-checkers and Wikipedia
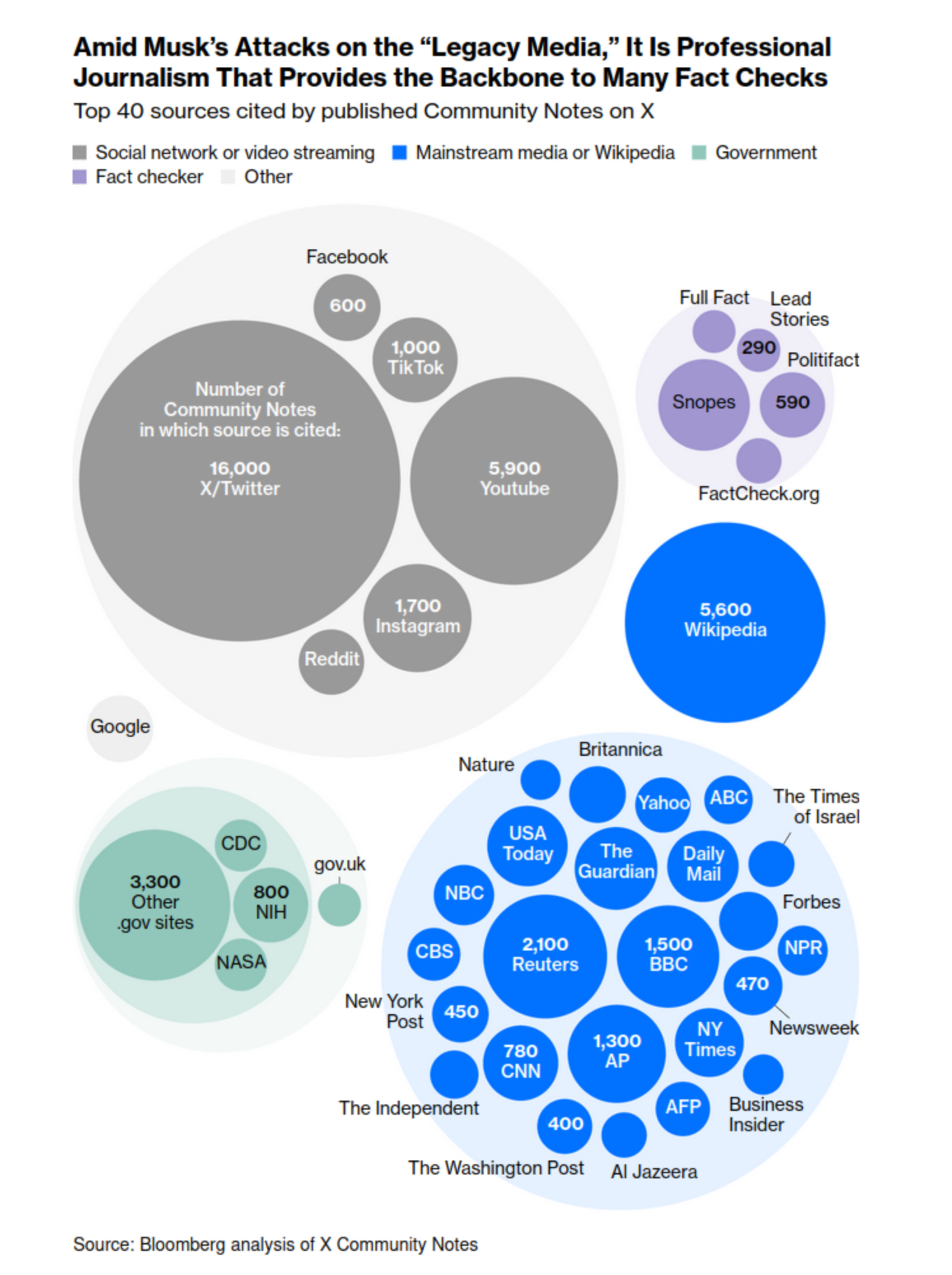
Source: Bloomberg (Community Notes Can’t Save Social Media From Itself, 18 March 2025)
Henry Farrell: The AI democracy debate is weirdly narrow
And by that he means focussed on deliberation (rather than non-deliberative struggles over power) and sortition (meaning representation of the publics, ‘in miniature’ so to speak).
Crudely put, we suggest that many AI people would prefer a version of democracy that gets rid of the politics. That not only misses the point of what democracy is, but risks ignoring a multitude of urgently important problems and questions. How does actually existing AI affect people’s understanding of politics? How might it reshape the ways in which groups and parties operate? What are the likely consequences of the efforts to turn LLMs into political-cultural chokepoints (see e.g. the Trump administration’s “anti woke AI” executive order)?
Link: The AI democracy debate is weirdly narrow
Dan Williams: The Case Against Social Media is Weaker Than You Think
Subtitle: The evidence that social media broke America is surprisingly weak. So why are so many people convinced it did?
Williams argues that what really happened in America was the Republican party specialised in the resentful non-educated, and this explains their dysfunction and disdain for the world of professionalised fact checking and elite-institutional managerialism
Link: The Case Against Social Media is Weaker Than You Think
Counterpoint: Kevin Munger (Attention is All You Need) argues that the cultural driver of Englightenment and Democracy - literacy - is over. We are now a society of “secondary literacy”
…And finally
Demonstrating that the current era of stupidity fashion for lamenting our levels of discourse predate the internet era, Calvin and Hobbes by Bill Watterson from 02 OCT 1994 and in There’s Treasure Everywhere (says michaelyingling.com).

END
Comments? Feedback? Examples of your work in AI training data? I am tom@idiolect.org.uk and on Mastodon at @tomstafford@mastodon.online