


The tuned stack
Reasonable People #38: an interlude about AI as an engine for understanding our intuitions

A slight departure from my normal programming about reasoning and persuasion, but I wanted to think out loud about how reactions to the latest wave of intelligence algorithms are driven by our intuitions, and in turn can be used to reveal the assumptions behind these intuitions.
The dream decoder
On February 28th, Yu Takagi & Shinji Nishimoto announced that their paper “High-resolution image reconstruction with latent diffusion models from human brain activity” had passed peer review and been accepted at an international scientific conference (CVPR 2023). The work, available in early-view/pre-print form since December, describes how they could take brain imaging data acquired in a MRI machine while participants looked at thousands of test images, and reconstruct the specific image the participant was viewing, using the brain imaging signals collected.
The results seem impressive:

Mind-reading AI! Those with the glass half full imagine rewatching film of their dreams, decoded from the signals given off by their sleeping brain. These with the glass half empty imagine CIA interrogation centres installing an fMRI machine and placing a quintuple order for sedative-hypnoptics.
But not so fast.
Let’s look at how it works to understand better how close to the fantasy of mind-reading this technology is.
Behind the curtain
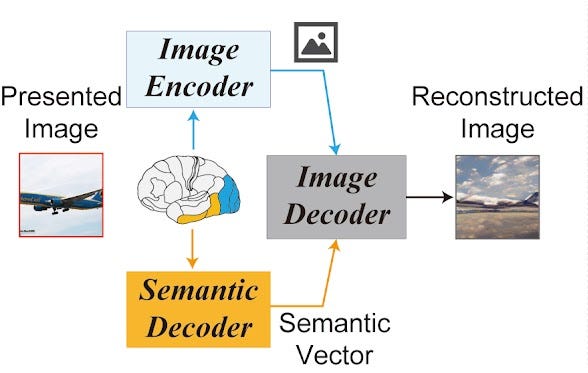
The authors are completely honest in presenting their model, although this elements may be easy to miss: the algorithm uses text descriptions of the images originally shown to the participants. These are generated separately by a “semantic decoder” which has been pre-trained on exactly these images and descriptions generated by a separate set of participants. These descriptions are then combined with a first guess at what the participant is seeing, and a “reconstructed image” generated.
Here’s a thread from @chhopsky with details


According to this deflationary account, we shouldn’t be so surprised that model can draw an image which fits the presented image, since it is given descriptions, and constraints in the form of a base pattern, and we already know that models like stable diffusion can generate images from text just fine thank you.
So should I be impressed or not?
In the early days of brain scan-aided mind reading you could publish a paper which showed you could tell which of 5 letters people were looking at. This task, while still technically impressive, is dramatically easier than the one one Takagi & Nishimoto attempt. If you know the set of answers, it is much easier to build an algorithm which guesses above chance from that set.
The Takagi & Nishimoto task is not guessing from a set, but generating reconstructed images. In the paper they are at pains to emphasise the lack of fine tuning required - their model does not need to be pretrained on the neural responses of the participants it is going to predict from (and - as far as I can tell - there are are bunch of other steps which machine learning engineers could use to augment the results which they don’t use). It still seems like an impressive, albeit, incremental result to me, but then IANAML (I am not a machine learning engineer).
The set of images used in this research was 10,000 images large. Is that a lot? It seems like enough to confound any simple strategy, even informed guesswork. Indeed, “the ten thousand things” is a Chinese idiom which means roughly “all things, the endless diversity”. But perhaps this is an arena where our intuitions might mislead.
The latent space of images may be smaller than we intuit
Stable diffusion generates images from text. It was the new astounding thing a few new astounding things back, before chatGPT. You can try it here stablediffusionweb.com.
Playing around with stable diffusion, I noticed a curious thing if you asked it to generate images of known places.
With famous places - like the Houses of Parliament - you would get realistic/plausible images, but with second-tier places the model would confabulate an image which was almost, but not quite, right. Like chatGPT with text, the model confidently confabulates. What interested me was that the confabulations were so close to the reality you needed to know the real place to confidently say the generated image wasn’t right.
At the risk of sounding like someone enthusiastically retelling one of their dreams, to the bafflement of all, here are a few places I know well, and how stable diffusion does.
Stable Diffusion. Prompt: St Catherine’s Hill, Winchester

St Catherine’s Hill is in Hampshire, next to the medieval city of Winchester, topped by a iron age hill fort, a small wood and a mizmaze.
Reality:

The stable diffusion image is so close: How does it get that from just the prompt “St Catherine’s Hill”? There is nothing in those words which demands a well formed hill, green rolling banks, a feature on the top. I assumed that St Catherine’s was too obscure to be directly trained into Stable Diffusion, like the House of Parliament may be, so how did it generate that image?
Here’s another; Sheffield Peace Gardens
Stable Diffusion:

Reality

Again, this is crazy good if you think the model has no specific knowledge of this location. Somehow it knows enough about what a peace garden is, what kind of city Sheffield is, to generate something plausible. If you didn’t know Sheffield I’d challenge you to know if the generated image was accuracte or not.
To some, this will just be another example of how these models are happy to generate bullshit answers (ie without regard to any ground truth), but I think they have another lesson for us.
The tuned deck
Last newsletter I wrote about Artificial reasoners as alien minds. Part of the thought is that AI may look like it is doing human thought, but that doesn’t mean it is achieving human-like competence in human ways. We should pay attention to our surprise at what it can do, because these may reveal that the task is easier than we thought (or easier for an artificial system) than we intuit.
Here’s an analogy from shopping. Amazon promises next day delivery. In some places, you can even get 1 hour delivery. This seems incredible, especially if we apply our intuition about normal shops to Amazon. To deliver what we want within the hour a normal shop would either have to be infinitely large, or infinitely smart, to order in what we want before we know we want it. But Amazon is not a normal shop and these intuitions don’t apply. Probably 95% of their orders for 1 hour delivery come from a set of 10,000 things, which is a large number, but not large for Amazon. They don’t have shops, they have warehouses, and can easily build one of these next to every city they promise delivery to. Or maybe it is 100,000 things which make up most 1 hour delivery orders, and they need ten warehouses per city. It doesn’t matter, the point is that the scale is completely beyond my normal experience of shopping, so that when - at 8am on a Tuesday - I realise I want an AAA battery, or the Shakira biography, or cat flea treatment, it seems like a miracle that they are able to get it to me by 10am, but really what feel to me like very idiosyncratic desires are in fact entirely predictable at the scale at which Amazon works.
The magician Teller said “Sometimes magic is just someone spending more time on something than anyone else might reasonably expect.”
There’s a trick Derren Brown televised where he predicted the winner at the dog races, to punter amazement. The ‘trick’ was that he bought bets for all dogs, so obviously he had the winning ticket. You can scale this up by buying all combinations of possible outcomes and seeming to predict 1000 to 1 chances. The trick works because buying all tickets isn’t an intuitive way make this prediction (and doesn’t make you any money, because you have to buy lots of losing bets). But if you have lots of resources you can astound punters who only buy one ticket at a time. (I wrote more about Derren Brown and how he manipulates our expectations about explanations here).
Dennett writes about another magic trick, The Tuned Deck, where the real trick is that there is no single trick. The singular title (“The” tuned deck) sets up the misdirection. The trick can be done differently each time, leaving audiences astounded as they discount possible explanations one by one.
Are we not entertained?
This is the argument: no, the Takagi & Nishimoto result does not show mind reading from brain scans. Technically impressive, definitely. Should we be amazed? If it was 1923 we’d be amazed by a digital calculator, but now we just take it for granted that this is the sort of thing digital devices are good at1 . We could scoff at the paper because it does not do more than "colour in the lines" according to a pre-learnt text description, we could scoff because the sample of images used was a finite 10,000. But also, perhaps, the fact that something like this is doable suggests that text descriptions can contain a surprising amount of information about how the world looks. In theory, reality is 3D, technicolour, endless variety is possible. But the actual world as we view it can be compressed : peace gardens will tend to look like this, hills near English cities like this, and so on. The algorithms will amaze us to the extent to which we don't evolve our intuitions about how hard the tasks we set them are.
References
Site for paper: High-resolution image reconstruction with latent diffusion models from human brain activity
Author Shinji Nishimoto tweets about paper acceptance at IEEE/CVF Conference on Computer Vision and Pattern Recognition, 28 Feb 2023
Preprint: Takagi, Y., & Nishimoto, S. (2022). High-resolution image reconstruction with latent diffusion models from human brain activity. bioRxiv, 2022-11.
Previously: Reasonable People #36 ‘Artificial reasoners as alien minds’
And more chatGPT links in RP #37 ‘Microarguments and macrodecisions’
PAPER: Maintaining transient diversity is a general principle for improving collective problem solving
Humans regularly solve complex problems in cooperative teams. A wide range of mechanisms have been identified that improve the quality of solutions achieved by those teams upon reaching consensus. We argue that all of these mechanisms work via increasing the transient diversity solutions while the group attempts to reach a consensus. These mechanisms can operate at the level of individual psychology (e.g., behavioral inertia), interpersonal communication (e.g., transmission noise), or group structure (e.g., sparse social networks). Transient diversity can be increased by widening the search space of possible solutions or by slowing the diffusion of information and delaying consensus. All of these mechanisms increase the quality of the solution at the cost of increased time to reach it. We review specific mechanisms that facilitate transient diversity and synthesize evidence from both empirical studies and diverse formal models—including multi-armed bandits, NK landscapes, cumulative innovation models, and evolutionary transmission models. Apparent exceptions to this principle occur primarily when problems are sufficiently simple that they can be solved by mere trial and error, or when the incentives of team members are insufficiently aligned. This work has implications for our understanding of collective intelligence, problem solving, innovation, and cumulative cultural evolution.
Smaldino, P. E., Moser, C. J., Velilla, A. P., & Werling, M. (2022, October 20). Maintaining transient diversity is a general principle for improving collective problem solving. https://doi.org/10.31235/osf.io/ykrv5
PAPER: How Experimental Methods Shaped Views on Human Competence and Rationality
Important archaeology on how popular science swung behind the idea that humans are irredeemably biased. It’s due, the paper claims, to a switch from using behaviour to responses to descriptions, as the foundational experimental method
Within just 7 years, behavioral decision research in psychology underwent a dramatic change: In 1967, Peterson and Beach (1967) reviewed more than 160 experiments concerned with people’s statistical intuitions. Invoking the metaphor of the mind as an intuitive statistician, they concluded that “probability theory and statistics can be used as the basis for psychological models that integrate and account for human performance in a wide range of inferential tasks” (p. 29). Yet in a 1974 Science article, Tversky and Kahneman rejected this conclusion, arguing that “people rely on a limited number of heuristic principles which reduce the complex tasks of assessing probabilities and predicting values to simple judgmental operations” (p. 1124). With that, they introduced the heuristics-and-biases research program, which has profoundly altered how psychology, and the behavioral sciences more generally, view the mind’s competences and rationality. How was this radical transformation possible? We examine a previously neglected driver: The heuristics-and-biases program established an experimental protocol in behavioral decision research that relied on described scenarios rather than learning and experience. We demonstrate this shift with an analysis of 604 experiments, which shows that the descriptive protocol has dominated post-1974 research. Specifically, we examine two lines of research addressed in the intuitive-statistician program (Bayesian reasoning and judgments of compound events) and two lines of research spurred by the heuristics-and-biases program (framing and anchoring and adjustment). We conclude that the focus on description at the expense of learning has profoundly shaped the influential view of the error-proneness of human cognition.
Lejarraga, T., & Hertwig, R. (2021). How experimental methods shaped views on human competence and rationality. Psychological Bulletin, 147(6), 535.[pdf]
BOOK: Persuasion in Parallel by Alex Coppeck (2022)
Argues that, persuasive information has a consistent persuasive effect on people’s support for policies. The "consistent” is important: contra the motivated reasoning hypothesis, Coppeck argues that the general pattern is similar size persuasive effects across both sides of political partisan populations.
More in this mastodon thread on the book and thesis
Coppock, A. (2022). Persuasion in Parallel: How Information Changes Minds about Politics. University of Chicago Press.
And finally…
I could probably use a different xkcd cartoon for every single newsletter, but this one is timeless when talking about machine learning

Comments? Feedback? Reports from the uncanny valley? I am tom@idiolect.org.uk and on Mastodon at @tomstafford@mastodon.online
END
Thank you to my daughter for making this point
I think the image of that locally famous hill from Stable Diffusion may be influenced by St Catherine’s Chapel in Abbotsbury btw, which is also locally famous.... https://images.app.goo.gl/Gqxcsc5L5kwVvBBZA